Presto on Amazon EMR
28 Dec 2018
Presto is a distributed query engine for running interactive datasets on a wide variety of sources. I found it blazingly fast on most of the datasets I use - typically in parquet format, after initial processing.
If you are using Amazon athena, you are already using presto as the engine behind the scenes. However, it is possible you want to install presto on EMR for a few reasons such as
- Control the version of presto you use and upgrade/pin the version when you choose.
- you might want to use it for running larger queries than the current limits imposed by Athena (30 minute query limit as of this writing).
- run it on hadoop files along with files on S3.
When creating the cluster, select Presto option and the option to choose the Hive metastore (if applicable)
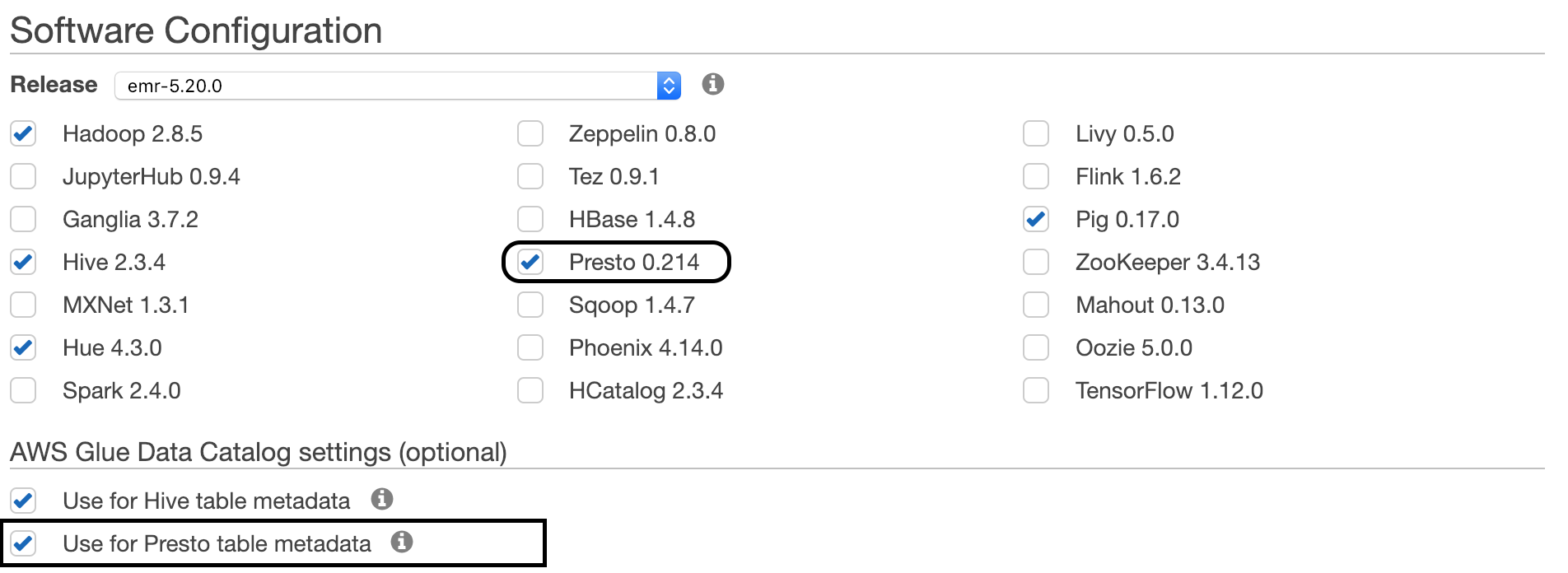
Once the cluster is created, you can ssh into the master node and access the presto CLI. Schema here maps to the “database” in athena. Catalog maps to the one-per-account catalog in Athena/Glue.
[hadoop@ip-xxx-xx-xx-xxx ~]$ presto-cli --catalog hive --schema sales_parquet
WARNING: History file is not readable/writable: /home/hadoop/.presto_history. History will not be available during this session.
presto:sales_parquet> show tables;
Table
----------------------------
fact_order_item
fact_order
fact_page_view
usage_snapshot
(4 rows)
Query 20181228_210708_00013_rapbe, FINISHED, 5 nodes
Splits: 70 total, 70 done (100.00%)
0:01 [4 rows, 177B] [7 rows/s, 316B/s]
presto:sales_parquet> select count(*) from usage_snapshot;
_col0
----------
84919353
(1 row)
Query 20181228_210718_00014_rapbe, FINISHED, 4 nodes
Splits: 47 total, 47 done (100.00%)
0:04 [84.9M rows, 0B] [22.1M rows/s, 0B/s]